
A data warehouse often has chronically too many unprocessed requests and at the same time the share of maintenance effort increases. The death blow for a data warehouse usually occurs when the effort for maintenance exceeds the effort for new development.
So it makes sense to automate the development and thus implement the new requirements more quickly. Automation takes place via a generalisation of problems, the solution is implemented as a gap text (template). For the specific solution, the corresponding context is then inserted into this template. The automatically generated results are more stable per se. If an error does creep in, the error can be eliminated for all uses at the same time by changing the template. This makes development and maintenance much faster.
Increasing productivity as a continuous process
Now you have an automation environment that can be perfectly optimised to further increase productivity. In ‘The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win’ by Gene Kim, Kevin Behr and George Spafford there is a good description of what such a continuous process can look like. The important thing here is to evaluate the work against its meaning and benefits:
- Business projects:
Creating business value through the processing of requirements with which new and up-to-date reports or data products are developed - Internal IT projects:
With which the workflow is to be improved - Changes:
Changes to the existing systems generated by the first two points - Unplanned work:
All work that was not actually foreseen and which prevented work on the three previous points from being carried out.
Unplanned work as a lever for acceleration
Monitoring unplanned work brings lasting positive change to a data warehouse. By targeting the causes of unplanned work and trying to avoid them in the future, resources are freed up, and the BI team can work more reliably. Planned tasks can be completed on time.
In addition, there is the happiness of sustainably reducing the friction in one’s own work area. This makes everyone involved happy and productive.
Unfortunately, one also quickly reaches limits here. The data warehouse is a complex matter with many dependencies. In the article ‘The Data Warehouse and the Seven Dependencies‘, these dependencies are presented as follows:

Shared responsibility reduces freedom of action
The data warehouse has sole control only over the technology. All other dependencies, such as the interface to the source systems, operations or the data deliveries to any recipients (front ends) are always a shared responsibility. This limits one’s own room for manoeuvre and the possibilities to reduce friction. Moreover, the majority of the requirements come from an area that has probably never worked properly since the beginning of IT: the definition and further development of the company’s own data, data management.
Don’t worry, the article still comes to a sensible conclusion and does not sink into lamentation. Please hold on for a moment and look at the problems this causes in the data warehouse. Problems that cannot be solved with automation:
- The correct and reliable provision of data by the source system:
This includes the quality of the captured data as well as delivery errors by the source system. - Lack of agreement on data:
This starts with the question ‘which entities?’ as well as with homonyms and synonyms, extends to uniform classification data within the framework of master data management and the question of data protection and security with its access rights.
Data management as a big cause
There is a common cause behind all these problems: data management in the company. Even delivery errors by the source system often turn out to be non-communicated developments in the data model.
As long as it is not clear to all participants which data is being discussed, misunderstandings will inevitably arise again and again. This does not mean that everyone has to have the same definitions for the data. A modern data warehouse supports more than one view of the data. However, this reinforces the need for a clear understanding of the underlying data. This is unfortunately a very old problem and the known solutions are:
- Gorilla:
Solution with constant escalation and support from top level management - Guerrilla:
Compensation for the lack of data management through additional work. This solution can extend to maintaining the company-wide data model in the data warehouse and having IT decide the access rights to the data.
Enough lamenting. What can a reasonable solution look like? Where is the middle way?
Solution orientation through concentration on needs
Whenever different parties have to work together on a result, conflicts of interest arise. To resolve a conflict, it is essential to know your own needs. What do I need to be able to produce a good solution here?
For a BI team, this translates to ‘what information does the data warehouse need to provide an optimal solution?’. To answer this, information is needed on the following three aspects (see diagram above):
- Data Vault Schema:
Exact details of the data or entities and their relationships for the Core Warehouse. - Security classes:
All information on data protection, data security and the access rights to the data - Business rules, KPIs and dimensions:
A precise description of the requirements for the desired reports and the necessary technical data transformations.
The business object model as an overview of the Core Warehouse
What is the minimum amount of information needed here? A good way is to use a simple conceptual model, the business object model. In a business object model, the business objects, their keys, few attributes and their relationships are stored.
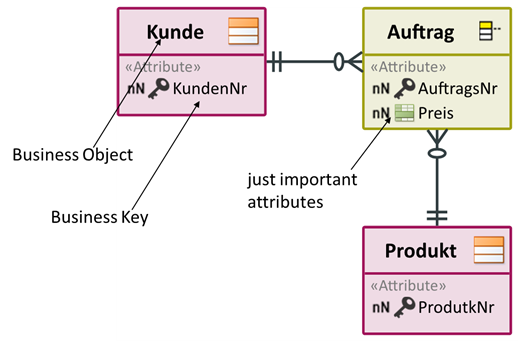
In its simplicity, a business object model is suitable for communication with the department. Here is another example of a simple representation of the shared data.

If you link these business objects with the source data, you have a first structure of the core warehouse. The attributes can now be assigned. The department receives a list on which it can classify data protection and security. The specifications can be made with the terms from the business object model and are thus unambiguous. All this information can be easily determined during the requirements elicitation and leads directly to the solution.
Future-oriented through pragmatism
Focusing on the information necessary for the data warehouse ensures a sufficient system without having to implement a complete data management. Should the company want to use further advantages of data management in the future and subsequently set up a project for company-wide data management. At that point, the BI team can use the new system and get the necessary information from there instead. Since this is the same information, only the source changes, the structure can remain the same.
This is neither gorilla nor guerilla, but pragmatic and solution-oriented. Only work necessary for the data warehouse is done. The required information is kept minimal and ultimately stems from the consideration: “What data do I need to create the data warehouse? This data can also be ideally used to drive further automation.
Data warehouse automation as a continuous improvement
Data warehouse automation is more than just a tool. A sustainable improvement can be achieved with a process for the continuous improvement of processes and a pragmatic, solution-oriented approach with the partners in the company. Contact us without obligation, we will be happy to show you solutions for better data warehouse automation.