
When you work with data warehouse automation for a while, you notice that the bottleneck shifts. The actual gain in time lags behind the gain in productivity. Both DWH Automation and DataOps only ever consider a section of the data warehouse. The data warehouse is a system with many communication interfaces. If productivity and quality are to be improved, the entire system must be considered. This avoids the danger of creating a local optimum that costs dearly elsewhere.
Concentration on services and information brings standardisation
Writing down the complete dependencies for a data warehouse is difficult because each data warehouse is organised differently and has its own architecture. Every company has its own organisational structure. Who sets the requirements on a data warehouse is different in each case. Therefore, in the following, functions are assumed with which a certain service is provided in cooperation or which supply certain information: Data, metadata, requirements. Our complete system becomes an abstraction of the data warehouse with a focus on clear interfaces and the information that is exchanged at the interface.
The architecture of the data warehouse always consists of several layers. How many layers it needs is a long debate. However, much more important than the layers in this consideration is the functionality that is provided. Because each functionality needs different information in the requirements for a successful implementation. If we organise the environment by functions and information exchange, the same should be true for the DWH. In essence, there are 3 rough steps that a data warehouse fulfils:
- the collection and integration of data
- the enrichment and correction of data according to requirements
- the provision of data
Four dependencies in the technical area
This is made possible by the underlying technology stack. Although the management of this technology stack may be in the hands of the BI team in smaller organisations,
- the choice of technology
- the checking the suitability
- the installation of hardware and software
- the development of guidelines for performant use
- etc.
are a separate functional area.
The data comes from source systems and is delivered via a defined interface mechanism, processed and delivered to one or more recipients or front end systems such as Cognos, Qlik, tableau or PowerBI. Recipients of data exports have been put on an equal footing with front end systems here: both receive data deliveries.
The structure of the data delivery should be independent of the respective recipient or front end. So that the preparation does not have to be adapted for other, different recipients or front ends. All there is to do, is putting the data into the desired form. This procedure ensures consistent results across all evaluations.
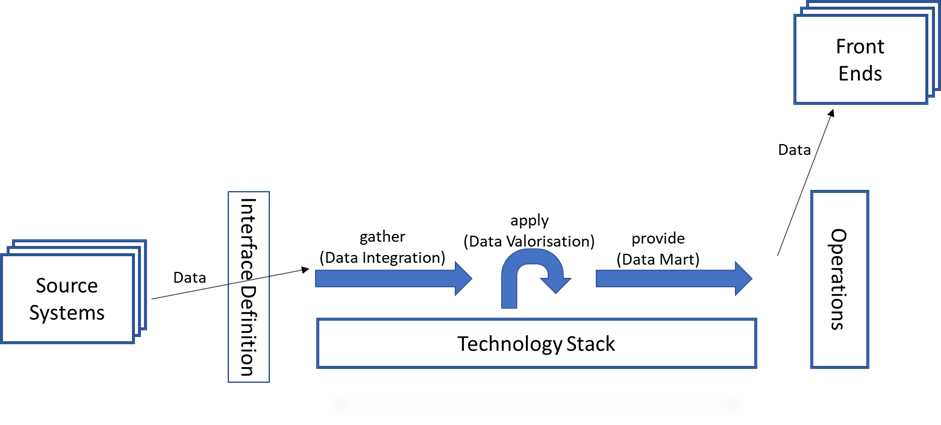
Last but not least, there is operations, which carries out the regular processing of the data as well as first and second level support.
These are four of the seven dependencies, of which the technology stack and operation are within the BI Team’s own sphere of influence. The data transfer must be agreed respectively with the suppliers and the recipients of the data. These dependencies are all already in the current scope of DWH Automation and DataOps.
The question of content cannot be solved in one dependency
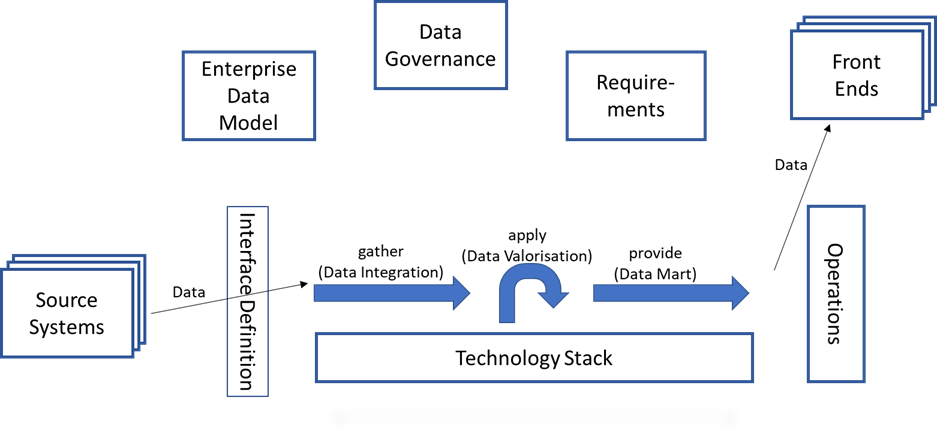
At this point, the complete area of requirements is missing. Inseparably linked to the requirements is the question: “What data is available?” Here lurks one of the greatest dangers for a data warehouse. If the enterprise data model has little to no definition, then a BI team can spend any amount of work filling these gaps. This complex is concluded with the question of access authorisations or the protection of data due to DSGVO or due to employee monitoring and a possible obligation to obtain approval from the works council or staff council. These protection and security classes are typically provided by data governance.
With these 3 boxes, all 7 dependencies are now in the picture. There may be other dependencies in individual cases, but with the following information most use cases are covered:
- the data to be used – Enterprise Data Model
- the access rights and the security classes of the data – Data Governance
- the requirements – Requirements
The enterprise data model does not help
As already mentioned, the issue of the enterprise data model is not a good idea in many companies. Many such initiatives have remained unsuccessful. The reason usually lies in the insistence on a standard definition, whereas different purposes often lead to different definitions. The whole issue is often a big controversy and distracts from quickly loading and evaluating the data. Is it possible to avoid this debate and still deliver valid data analysis? What information does it actually take to successfully create a data warehouse?
Agreement is needed with the respective clients on the data to be used. A simple conceptual data model in which the business objects are modelled with their business key helps here. If no key is available, this is also valuable information. Such a business object model enables a quick understanding of the data to be used.
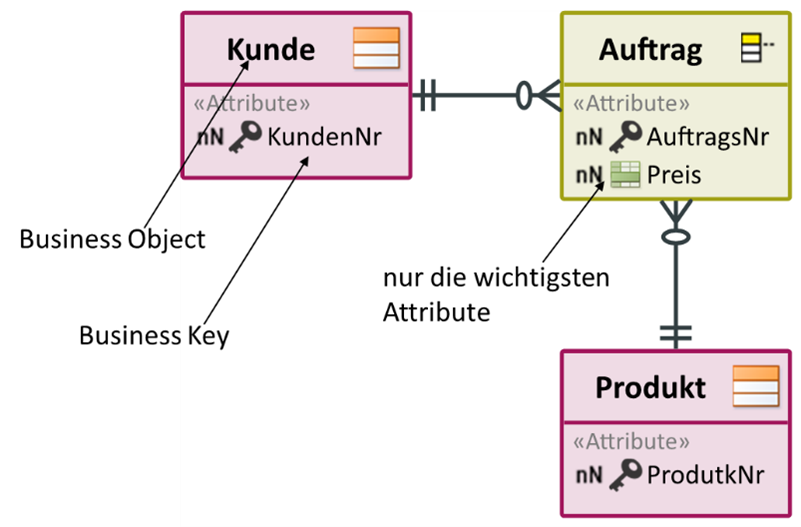
Targeted conceptual modelling offers more possibilities
These business objects can be linked to the data from the source systems. In addition, the schema for the Data Vault can be generated from this conceptual data model. A precise derivation from conceptual to Data Vault is described in the article ‘Conceptual Data Vault Model‘ by Jovanovic and Bojicic. The core warehouse is thus determined by the conceptual model. The necessary transformations can be specified via the assignment to the source. This complete discussion can be conducted with the department. With the help of the conceptual model, a common language is created that can be used in the formulation of the requirements. With the business object model, a glossary of relevant data is created.
Thus, we have built a bridge between the source systems, the data used, the requirements and the data governance. If the next internal client has a different view of this data, then this can be described in a different business object model. By mapping the source data, the differences can be explained based on the actual data. With the combination of Raw Vault and Business Vault, Data Vault offers the possibility to calculate the differences separately and to map the deviations as model extensions. Unification is no longer necessary; the data warehouse can provide multiple views of the same facts.
This is currently not always common in this form, but it saves the BI team all discussions about the standardisation of the data and concentrates the resources on the provision of the data. This offers a concentration on the central tasks by exhausting one’s own possibilities. Moreover, the question arises whether a unified view of the data is always so meaningful when fundamentally different activities are considered on the basis of the data. Experience shows that when the differences in viewpoint are clearly stated, communication becomes easier for all involved. It is the recognition of each other’s expertise that has a healing effect here. A more detailed in-depth consideration would be worth a separate article.
If necessary, a translation from the business object model to data governance must take place. Ideally, the protection and security classes are already defined on the source data and thus provide a unique security and authorisation classification for the DWH. If there is no data governance, it must be defined. The legal regulations on DSGVO or also on co-determination are very clear. This responsibility must be clearly regulated in the data warehouse accordingly.
This changes the picture as follows:
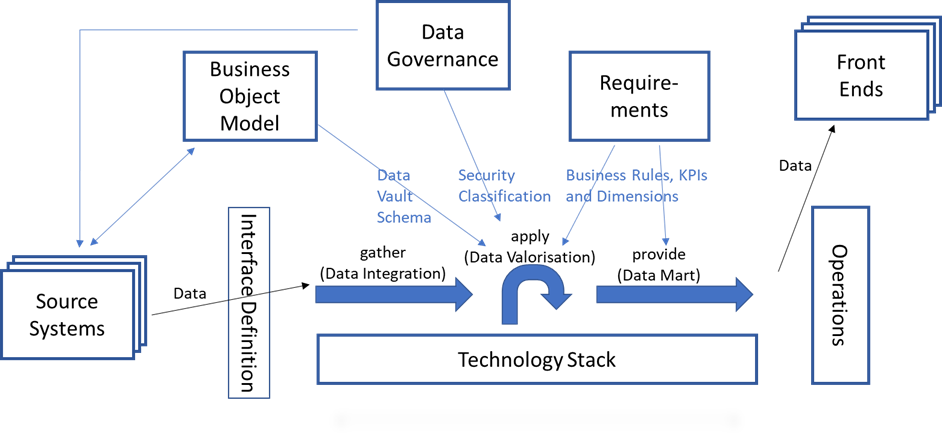
Complete view as a starting point for overarching improvements
The total number of dependencies and the associated need for communication with 7 dependencies is exceedingly high. If one looks more closely at the individual parts, one discovers dependencies between the seven areas. Even in this quick overview, further approaches for improved cooperation can be found. By focusing on functions and their data, information and requirements, collaboration can be described using metadata. With this metadata, further automations can be realised.
The classification allows a clear assessment of which activities are needed to create the data warehouse. This can be used to reduce off-target activities to the relevant areas or even eliminate them altogether. When adapting to your own data warehouse, the picture of the dependencies must be compared and, if necessary, supplemented. At the same time, the question arises whether these are really needed for the creation of the data warehouse.
The next step is to define key figures that can be used to monitor performance and quality in this system. Then, in addition to the model of the system, one also has the parameters for a constant improvement of the data warehouse.