
Probably the best-known approach to automation is the Toyota Production System. It is considered a general model for the automation of complex processes. DevOps has shown that these principles can be transferred to the development and operation of software. One of the central theses: Only standardised steps in a process can be automated.
A production process has a material flow that leads to the desired product. Data Warehouse Automation (DWA) has several process and data flows. On one hand, there is the data to be prepared, the actual product. On the other hand, there are the metadata flows that generate essential parts of the DB schema and the code, as well as the development steps with which the data preparation process is implemented, tested and put into production. Which of these flows is the central flow for the initial standardisation and the subsequent optimisation considerations?
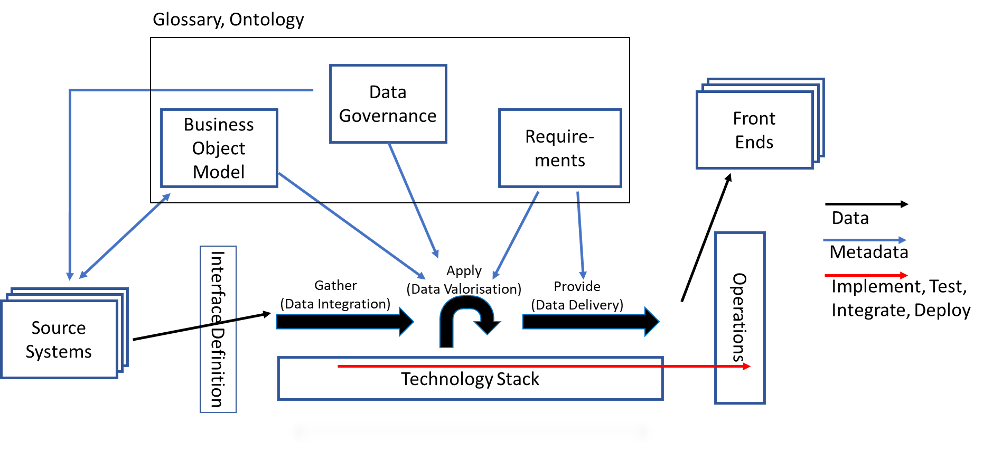
The driving process here is data preparation (black arrows). Everything else depends on it and is always aligned with the data preparation process. The order of the process steps determines the need for metadata and the content of the activities for implementation, testing, integration and deployment. The result is described in the development guidelines and the implementation procedure.
In BI, there is no standard process for data integration, no clear standard as to which steps are carried out in which order. Even within a data warehouse, one often sees the same problems solved differently, be it through different functionality or also in different phases of the data integration process.
One example is the question in which layer the data is brought into a common structure after a system change. This integration can take place on any layer in a data warehouse. The decision for a certain layer is usually determined by the question: ‘What can be implemented the fastest?’
Standardisation is often perceived as an obstacle to rapid implementation. However, the short-term advantages of rapid implementation are quickly outweighed. In the long term, standardisation reduces the total number of solution patterns within a data warehouse. Fewer solution patterns reduce complexity because fewer solutions need to be understood, implemented and maintained.
Standardisation is what makes automation possible in the first place. And maintenance also becomes easier, as changes can also be automated. If a solution pattern is used often enough, it is worth writing a procedure that converts all existing logics to the new logic. Overall, this reduces the risk that the maintenance effort will exceed the effort of further development. The data warehouse becomes more sustainable and can survive longer than the usual 3-5 years.
Standard procedure based on the 3 phases
In the blog post ‘Principles for a strong and intuitive DWH architecture‘, 3 phases for a data warehouse are presented on the basis of generally valid principles.

On this basis, concrete steps for data processing can now be described. For this description, the layers of the data warehouse are now also needed. With the persistence of the data, specific actions become necessary. The result is an architecture in which both the transformations (‘data in motion’) and the layers (‘data at rest’) are described.
This architectural model is not ideal for every data warehouse, because every company, every enterprise data model and every technology, software or/database used brings its own requirements. However, it is important to have a good starting point for discussing the adaptation and further development of the architecture. The architectural model as a reference on which a common understanding is made possible for all participants and on which the respective deviations are described. In this way, misunderstandings can be reduced to a minimum.
Steps towards data integration –
best case scenario
When standardising, it makes sense to start with the basic functions and then add to them. In this way, unnecessary tasks can be found out. The division of process steps according to E. W. Dijkstra (https://en.wikipedia.org/wiki/Separation_of_concerns) leads to modular process steps without repetition of functionality.
What steps are needed if the data is of impeccable quality? When there are no problems with data quality, no incorrect keys and no problems with data delivery. What does a data warehouse need to do in the best case to deliver insights on perfect data?
This is what a simple best-case process might look like:
- Load new data
- Integration of the data (via business keys)
- Store data historically
- Create dimensions
- Create facts
- Create facts for derived measures
- Provide data
Seen in this light, ideal data integration is relatively simple. The new data comes into the Stage. From there, they are integrated via the business keys and historically stored in the Data Vault. The base measures are already available in the correct form. Only the dimensions and the facts need to be created for the data mart. On the data mart, the facts are calculated with the derived measures and prepared and exported for the front-end tools. The decision as to whether these derived facts need to be persisted must be made individually in each case. There is no task for the Business Vault in this picture. The data is already correct, there is nothing to do in the business vault.

What could possibly go wrong?
In a data warehouse, data always needs to be adjusted for many reasons. Most of the adjustments can be divided into the following categories:
- The data is incorrect and must be corrected.
- The data comes from different sources and differ in the conceptual model, i.e. they do not have the same business objects and keys. An integration of this data requires a more or less complex logic.
- Data or facts are missing but can be calculated from existing data.
- To improve the performance when extracting the data, PIT or bridge tables may be required.
A treatment of bitemporal data as a special case is excluded here because not every data warehouse has bitemporal data. Moreover, bitemporality would be an extension of this architectural model. Nothing stands in the way of a later extension to include bitemporal aspects.
Correct data
As a rule, correcting the data in the data warehouse should be avoided. It is always better if the causes for incorrect data or bad data quality are corrected in the source system. However, this is not a general principle, as there are too many exceptions and deviations. Sometimes the data simply has to be corrected in the data warehouse.
Apply: Correct data
As described in the blog post ‘Principles for a strong and intuitive DWH architecture‘, all data should always be loaded. A correction of the data only takes place in the Business Vault.
Gather: Adapt data types
An exception to this is the correction of the data types. Especially when the data is not written directly into the database, the data types are initially all only in the data type text. Although the exporting system strictly checks the data types and also exports them correctly. Or there are cases where the source system uses a different data type, e.g. for performance reasons. In SAP, many date formats are stored as text and certainly always contain a valid date. In all these cases, it makes sense to correct these data types already in the stage when loading.
Gather: Check data structure
There is one situation in which correction of the data is simply not possible: If the data is delivered by file and has to be loaded into the database, then the structure of the data must be correct. Therefore, the data structures must be checked during the database import.
Additional logic for data integration
A data model answers the questions: Which business objects exist in the company? Which key do I use to identify the business objects? What relationships do these business objects have? Which properties should be stored for them?
For data integration, business object, key and relationship are important. Unfortunately, there is rarely one view of a business object in the company. The more important something is, the more definitions there are for it. In the sense of the principle ‘One Version of Facts – Multiple Truths’, the BI team harmonises these questions into a fact store. The differentiation then takes place via business rules specified by the business department.
Here lies one of the central intellectual achievements in the development of a DWH: the correct conception of the business objects from the data models of the source processes and the wishes of the business departments. If too little is done, the data warehouse is only a historized version of the source systems. If too much is done, a part of the work may have to be dismantled for a new department.
Gather: Normalise data
Sometimes the data content does not have to be changed at all, it is sufficient to normalise the attributes of a business object to the desired key. This also includes the transformation from a technical key to a business key. This was explained in more detail in the blog post ‘Actively designing data interfaces pays off’. It also has the advantage that the correct delta can always be formed on this basis and thus makes uniform loading procedures into the Raw Vault possible.
Gather: Create Delta
In addition, it makes sense to adopt the abstraction from this paper into the architecture and store the data to be loaded as a delta.
Unclear: generalisation / specialisation
The resolution of a generalisation or grouping of data in a specialisation can either be done on the way to the Raw Vault or later in the Business Vault. Here, the wishes according to the business object model are decisive. Therefore, this point is not listed separately in the architecture diagram.
Apply: Complex integration logic
All further actions for data integration are complex and require a precise specification – business rules – by the business department. These requirements change over time and differ between departments. Thus, these are actions within the framework of data valorisation.
Apply: Complex fact logic
Sometimes the correct data is either not available or simply stored incorrectly. Nevertheless, this data can be calculated with the help of more or less complex logic. Most of the time, this is easier and faster than adapting the existing systems. Sometimes this data cannot be captured at all. It lacks the time, the opportunity or the legal basis for this capture. An estimate or calculation is the only alternative left. Like any business logic, this logic is subject to change and should therefore be calculated in the Business Vault.
The extended architecture picture for data integration
The architectural model is thus extended by several work steps. Each work step is optional and highlighted in blue in the graphic. A blue work step is therefore only carried out if necessary.
With this more precise description, the individual layers in the architectural model can also be described more accurately.

This architectural model ensures standardisation of data warehouse development. If there is something that does not fit into this picture right away, it can be integrated here and the decision about the extension can be documented for future developments. The architecture grows with and in response to the challenges. This means that the wheel does not always have to be reinvented. One can fall back on existing solution patterns. The total number of patterns used decreases – and with it the complexity, which in turn makes maintenance and servicing more cost-effective. The standardised work steps can be automated and the speed of development increased.
The question arises whether these steps are actually optimal? After all, a rough approach was chosen when cutting the process steps in order to first develop a common basis for discussion. Consequently, a framework is needed according to which this architectural model can be examined, evaluated and improved. The model needed for this is described in more detail in the following blog post.