
When implementing a data interface for BI, it is important to secure these interfaces. If the data submissions are not reliably available at the agreed time, if the deliveries are incorrect or incomplete, then unplanned work arises. As a result, development time must be diverted for corrections. This must be avoided.
The first two blog posts presented how interfaces are best built and kept simple. The reduction of possible options brings a reduction in complexity. This also means that fewer mechanisms are needed to secure the data interface.
The following target picture emerges from the considerations in the previous blog posts:

Since the question of whether a database import takes place is relevant for securing data delivery, a possible DB import was added to the target picture respectively.
The following topics are to be examined for interfaces:
- Is the delta that has been handed down correct?
- Is the data in the correct structure?
- Is the content of the data correct? Has there been any fundamental change in the data capture?
- Are the changes delivered in the correct order?
Testing the delta
It happens: The data warehouse deviates from the data in the operative system. A problem that is solved fully automatically by simply pulling all the data with the next delivery. In this way, errors in the delta determination can also be found and corrected. A complete data extraction is transmitted to the data warehouse as an inventory delivery and checked against the previously loaded data. As a result, all differences are found.
The test can be performed against the Stage or against the Core Warehouse layer. A check can only be made against the stage if a persistent staging area (PSA) with all previously delivered records is available. The completeness check can only be performed against the currently valid records. The beauty of this solution lies in the fact that the discrepancies are already in the correct format and can be used immediately to correct the data. The mechanisms for comparison here are the same as for determining the delta. The basic decision to always load only the delta also helps here and enables checking and determining the necessary correction records in one step.
When checking against the Core Warehouse, on the other hand, it is advisable to use a view to bring both – the corresponding part of the Core Warehouse and the inventory delivery – into the structure of the corresponding stage tables. After the comparison, the deviations are immediately available in the correct form for the subsequent correction.
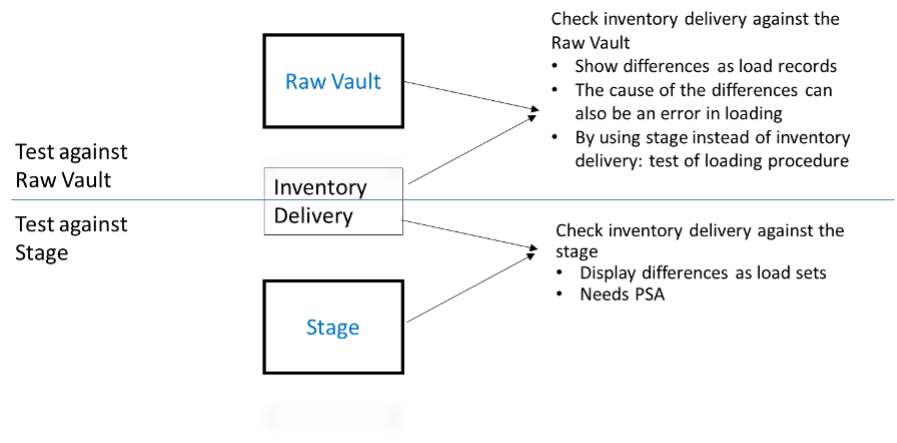
This approach can also be used very well to check the loading of the Core Warehouse. The test against the stage shows whether all data has been transferred to the Core Warehouse. If only individual delta deliveries are tested for correct loading, the tables from the warehouse must be filtered accordingly. It is recommended to test the correct loading in order to exclude the possibility that the error occurred in the loading routines when comparing the inventory delivery against the Core Warehouse.
Use inventory delivery for deletion detection
Sometimes it is not possible to identify the deleted records and deliver them to the stage. In these cases, it makes sense to regularly extract all keys from the source system. This is only a small amount of data that can be exported daily or weekly.
The deleted records can be determined by comparing the current delivery with the last export. This is how deleted keys, and their records are determined. For these records, the deletion indicator is then loaded into the status satellite. A simple solution to an otherwise arduous problem.
Faulty data structures
Everything is constantly changing. Source systems are maintained and further developed. This sometimes also changes the data model. Good communication helps and ensures timely planned changes in the data warehouse.
If the communication with the development team of the source system does not work, the data will not arrive in the desired structure. This problem does not occur with a CDC tool or when the data is copied directly into the database. In this case, the difference in the structures usually causes the routines to be aborted during data provision.
If the data is delivered in files and an error occurs, it must first be determined whether it is a transmission error or a change in the structures. This distinction is important to determine whether the data can still be loaded.
If the data is delivered via a file transfer where the metadata is not automatically included, i.e. it is neither JSON nor XML, then no distinction can be made. The delivered data does not fit the target structure. No adaptation can take place. The data cannot be loaded.
If one wants to safeguard this case, then it is recommended to load or check the data using a metadata structure provided.
Incorrectly transmitted data
To load or not to load, that is the question. If the data cannot be loaded, further processing stops. There is no updating of the evaluations. If loading the data causes an abort, someone has to check this data and correct the error or decide that 98% of the data is correct and further processing can run with a smaller number of records.
This is the unplanned work mentioned at the beginning. And in this case, it can hardly be prevented. Loading corrupt data makes little sense. The clean-up work is too time-consuming. Which does not mean that other files from this delivery cannot be loaded. There are no dependencies when loading the data up to the Core Warehouse, as the possibility for late arriving facts should always be granted. The only exception would be files where a normalisation action is intended with the corrupt file. Of course, these are not to be loaded.
Changes in the data structure
With the help of the metadata, changes in the data structures can be detected. The following changes are possible in the supplied data structures:
- Change of a data type
- Delete one or more attributes
- Deleting tables
- Adding one or more attributes
- Adding tables
The change of a data type can be ignored if the new data type is automatically convertible into the previous structures. However, if the data type is not convertible, the attribute can only be filled with NULL when it is transferred to the Core Warehouse. In a subsequent step, a new attribute with the new data type must be created. Later, it can be decided whether the previous data will be transferred to the new format and whether the previous attribute will be removed from the core warehouse.
Deleted attributes are simply left empty in the further process. Loading can take place as usual. If it is a necessary attribute that must be present to fulfil a logic, then this error can be handled in the appropriate place. Within the loading layer, this knowledge is not available. Apart from that: What if the attribute is used in other places and does not have this relevance there? These evaluations would also be blocked. It is better to decide later on a differentiated basis per data product whether the quality is sufficient for publication.
Deleted tables are not loaded.
New attributes could be loaded. If the mapping of the existing attributes is analysed, it can be determined where this attribute can be usefully added in the core warehouse and in the data mart. The implementation of this functionality requires the ability to automatically adapt the data structures in the data warehouse. But be careful: For legal reasons, the correct data governance data is required for the data security class and the data protection class. Without the likewise automatic access to the correct protection classes, this functionality must not be implemented, as otherwise personal data may be freely available for evaluation.
New tables are not loaded initially. No data source should be made available without an explicit request.
Systematic change of content through an adaptation of use
Up to this point, the completeness and structural integrity of the data has been checked. But how to check the content? Which changes in the content are problematic at all?
When creating the loading procedures for a data warehouse, the data is analysed to determine whether the desired results can be generated from the content. If content and information needs do not match, either an adjustment of the capture in the source systems or an adjustment of the data via special requirements – the so-called business rules – takes place.
What if the data capture in the source systems changes and the data is no longer sufficient? What if the data quality is not sufficient? What if the requirements for a business rule are no longer sufficient?
The information for such a check is not available in the loading layer. The business rules run in a later step. It has to be checked there whether the prerequisites are all still sufficient. In principle, the loading of the data takes place independently of the business rules. In the sense of the Single Responsibility Principle, the knowledge of the business rules should only be available in one place. The check of the assumptions must also take place there.
Data quality can certainly be checked in the loading layer. However, this is a separate step and is independent of the loading processes. Data quality checks can be time-consuming and should therefore be carried out independently from the data loading process. Hence, data quality checks should only be implemented on request or investigated specifically in individual cases. The assessment of whether the content is sufficient for reporting is entirely up to the department.
Ensure the correct sequence of deliveries
The data should be loaded in the same order as it was exported. The order is essential, especially when only changes are loaded. In most cases, the order of the load is rarely different from the order of the export. If there are differences, the problem can be corrected by reloading the data, as the error is within a small timeframe. Alternatively, the problem can be solved with an inventory delivery.
It is more difficult if a sequence cannot be ensured. Some message systems do not deliver the data in send order. In these cases, the date of the export of the data at the source is needed. Before accessing the data in the Core Warehouse layer, the sequence of the data records must be corrected using this time information.
This is not to be confused with a subsequent change or correction of the data or with a technical validity of the data. The export date serves solely to reconstruct the correct sequence of changes.
Correcting the order in which data is accessed is an additional task that can be avoided through better interface design. It is best to ensure that data is delivered in the order in which it was changed in a systematic way. The interface becomes simpler because this prevents the wrong order of change data from occurring in the first place.
Save data deliveries
The fewer variants are used ingesting the data, the easier it is to secure the data transmission. Systematic safeguarding of the delivery sequence ensures correct access to the data.
An abort with system standstill causes unplanned work, which is why an abort of the loading process should only take place if the data is presumably corrupt. Changes to the data structure should be intercepted with the help of metadata. It is better if changes to the source systems are communicated in good time and thus dealt with as part of the normal development work. A regular exchange with the source systems on future development work prevents surprises and saves a lot of trouble.