
Der wohl bekannteste Ansatz zur Automatisierung ist das Toyota-Produktionssystem. Es gilt als allgemeines Modell für die Automatisierung komplexer Prozesse. DevOps hat gezeigt, dass sich diese Prinzipien auf die Entwicklung und den Betrieb von Software übertragen lassen. Eine der zentralen Thesen: Nur standardisierte Schritte in einem Prozess können automatisiert werden.
Ein Produktionsprozess hat einen Materialfluss, der zum gewünschten Produkt führt. Die Data Warehouse Automation (DWA) hat mehrere Prozess- und Datenflüsse. Zum einen gibt es die aufzubereitenden Daten, das eigentliche Produkt. Zum anderen gibt es die Metadatenflüsse, die wesentliche Teile des DB-Schemas und des Codes generieren sowie die Entwicklungsschritte, mit denen der Datenaufbereitungsprozess implementiert, getestet und produktiv gesetzt wird. Welcher dieser Flüsse ist der zentrale Fluss für die initiale Standardisierung und die darauffolgenden Optimierungsbetrachtungen?
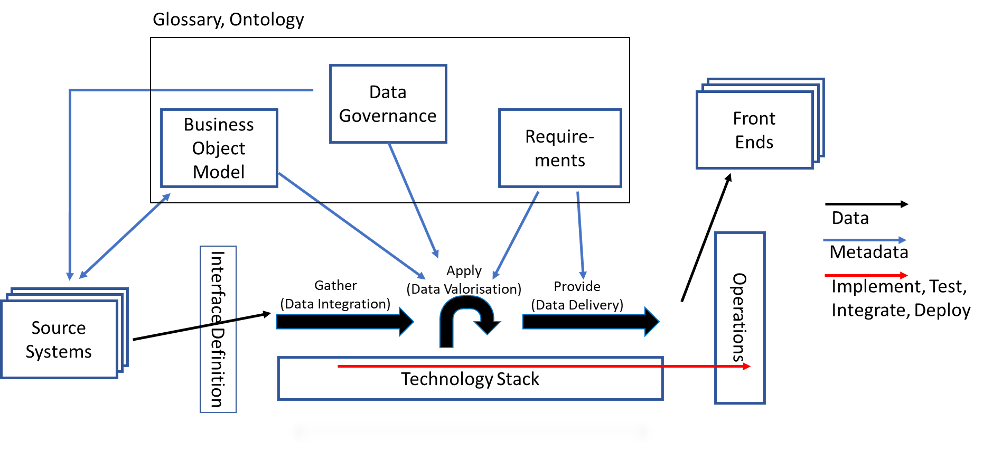
Der treibende Prozess ist hier die Datenaufbereitung (schwarze Pfeile). Alles Weitere hängt davon ab und richtet sich letztlich immer nach dem Datenaufbereitungsprozess aus. Die Reihenfolge der Prozessschritte bestimmt den Bedarf an Metadaten und den Inhalt der Tätigkeiten für Implementierung, Test, Integration und Deployment. Das Ergebnis wird in den Entwicklungsrichtlinien und im Implementierungsvorgehen beschrieben.
In BI gibt es keinen Standardablauf zur Datenintegration, keinen klaren Standard, welche Schritte in welcher Reihenfolge ausgeführt werden. Selbst innerhalb eines Data Warehouse sieht man oft die gleichen Probleme unterschiedlich gelöst, sei es durch unterschiedliche Funktionalität oder auch in unterschiedlichen Phasen des Datenintegrationsprozesses.
Ein Beispiel ist die Frage, in welcher Schicht die Daten nach einem Systemwechsel in eine gemeinsame Struktur gebracht werden. Diese Integration kann auf jeder Schicht in einem Data Warehouse erfolgen. Die Entscheidung für eine bestimmte Schicht wird meist von der Frage bestimmt: ‚Was lässt sich am schnellsten implementieren?‘.
Die Standardisierung wird hierbei oft als Hindernis einer schnellen Implementierung wahrgenommen. Dabei sind die kurzfristigen Vorteile einer zügigen Implementierung schnell aufgewogen. Denn langfristig reduziert die Standardisierung hingegen die Gesamtzahl der Lösungsmuster innerhalb eines Data Warehouse. Weniger Lösungsmuster reduzieren die Komplexität, weil weniger Lösungswege verstanden, implementiert und gepflegt werden müssen.
Die Standardisierung ermöglicht erst die Automation. Und auch die Wartung wird leichter, da Änderungen ebenfalls automatisiert werden können. Ist ein Lösungsmuster oft genug verwendet, lohnt es sich, eine Prozedur zu schreiben, die alle bestehenden Logiken auf die neue Logik umsetzt. Insgesamt sinkt so die Gefahr, dass der Wartungsaufwand den Aufwand der Weiterentwicklung übersteigt. Das Data Warehouse wird nachhaltiger und kann länger als die üblichen 3-5 Jahre überleben.
Standardablauf auf Basis der 3 Phasen
Im Blogbeitrag ‚Prinzipien für eine starke und intuitive DWH Architektur‘ werden anhand von allgemeingültigen Prinzipen 3 Phasen für ein Data Warehouse vorgestellt.

Auf dieser Basis lassen sich nun konkrete Schritte für die Datenaufbereitung beschreiben. Für diese Beschreibung werden nun auch die Schichten des Data Warehouse benötigt. Mit der Persistenz der Daten werden eigene Aktionen notwendig. Das Resultat ist eine Architektur, bei der sowohl die Transformationen (‚data in motion‘) als auch die Schichten (‚data at rest‘) beschrieben sind.
Dieses Architekturbild ist nicht ideal für jedes Data Warehouse, denn jedes Unternehmen, jedes Unternehmensdatenmodel und jede eingesetzte Technik, Software oder/ Datenbank bringt jeweils eigene Anforderungen mit. Es ist jedoch wichtig, einen guten Startpunkt für die Diskussion über die Anpassung und die Weiterentwicklung der Architektur zu haben. Das Architekturbild als Referenz, auf der allen Beteiligten ein gemeinsames Verständnis ermöglicht wird und auf der die jeweiligen Abweichungen beschrieben werden. So lassen sich Missverständnisse auf ein Minimum zu reduzieren.
Schritte der Datenintegration –
Best-Case-Szenario
Bei der Standardisierung ist es sinnvoll, mit den Grundfunktionen zu beginnen und diese dann zu ergänzen. Auf diese Weise lassen sich unnötige Aufgaben herausfinden. Die Aufteilung der Prozessschritte nach E. W. Dijkstra (https://en.wikipedia.org/wiki/Separation_of_concerns) führt zu modularen Prozessschritten ohne Wiederholung von Funktionalität.
Welche Schritte werden benötigt, wenn die Daten in tadelloser Qualität vorliegen? Wenn es keine Probleme mit der Datenqualität, keine inkorrekten Schlüssel und keine Probleme bei der Datenlieferung gibt. Was muss ein Data Warehouse im besten Fall leisten, um Erkenntnisse über perfekte Daten zu liefern?
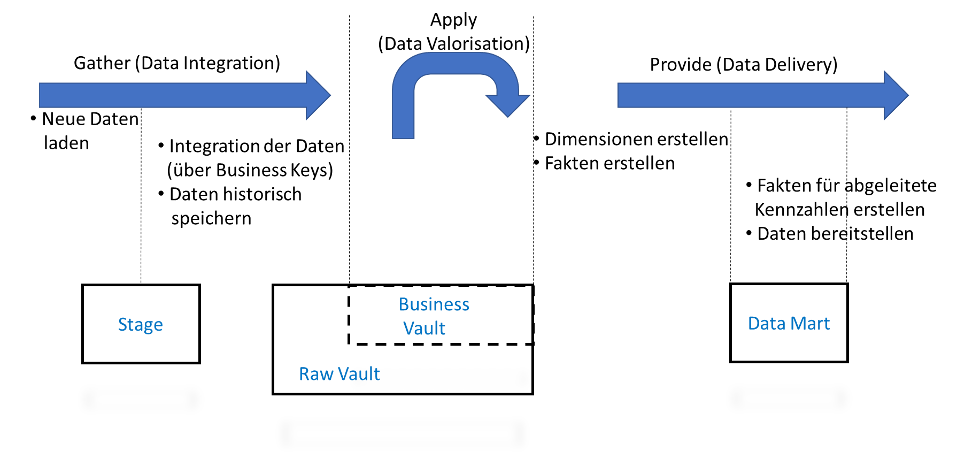
So könnte ein einfacher Best-Case-Prozess aussehen:
- Neue Daten laden
- Integration der Daten (über Business Keys)
- Daten historisch speichern
- Dimensionen erstellen
- Fakten erstellen
- Fakten für abgeleitete Kennzahlen erstellen
- Daten bereitstellen
So gesehen ist eine ideale Datenintegration relativ schlicht. Die neuen Daten kommen in die Stage. Von dort werden sie über die Business Keys integriert und historisch im Data Vault abgelegt. Die Basiskennzahlen stehen bereits in der korrekten Form zur Verfügung. Für den Data Mart müssen lediglich die Dimensionen und die Fakten erstellt werden. Auf dem Data Mart werden die Fakten mit den abgeleiteten Kennzahlen berechnet und für die Frontend-Werkzeuge aufbereitet und exportiert. Die Entscheidung, ob diese abgeleiteten Fakten persistiert werden müssen, ist jeweils individuell zu treffen. Für den Business Vault gibt es in diesem Bild keine Aufgabe. Die Daten sind bereits korrekt, also gibt es im Business Vault nichts zu tun.
Was kann da schon schief gehen?
In einem Data Warehouse sind die Daten immer aus vielerlei Gründen anzupassen. Die meisten der Anpassungen lassen sich in folgende Kategorien unterteilen:
- Die Daten sind falsch und müssen korrigiert werden.
- Die Daten stammen aus unterschiedlichen Quellen und unterscheiden sich im konzeptionellen Modell, d.h. sie haben nicht dieselben Geschäftsobjekte und Schlüssel. Eine Integration dieser Daten bedarf einer mehr oder minder komplexen Logik.
- Es fehlen Daten bzw. Fakten, die sich jedoch aus den bestehenden Daten errechnen lassen.
- Für eine bessere Performance beim Auslesen der Daten braucht es unter Umständen noch PIT bzw. Bridge Tabellen.
Eine Behandlung von bitemporalen Daten als Spezialfall wird hier ausgeklammert, da nicht jedes Data Warehouse bitemporale Daten hat. Zudem wäre die Bitemporalität eine Erweiterung dieses Architekturbilds. Einer späteren Erweiterung um bitemporale Aspekte steht nichts im Weg.
Daten korrigieren
In der Regel sollte eine Korrektur der Daten im Data Warehouse vermieden werden. Es ist immer besser, wenn möglichst die Ursachen für die falschen Daten bereinigt werden und die Datenqualität auch im Quellsystem verbessert wird. Das ist jedoch kein generelles Prinzip, da es hier zu viele Ausnahmen und Abweichungen gibt. Mitunter müssen die Daten einfach im Data Warehouse korrigiert werden.
Apply: Daten korrigieren
Wie im Blogbeitrag ‚Prinzipien für eine starke und intuitive DWH Architektur‘ beschrieben, sollen immer alle Daten geladen werden. Eine Korrektur der Daten erfolgt erst im Business Vault.
Gather: Datentypen anpassen
Eine Ausnahme hierzu ist die Korrektur der Datentypen. Gerade wenn die Daten nicht direkt in die Datenbank geschrieben werden, sind die Datentypen zunächst einmal alle nur im Datentyp Text. Obwohl das exportierende System die Datentypen streng prüft und auch korrekt exportiert. Oder es gibt Fälle, in denen das Quellsystem einen anderen Datentyp verwendet, z.B. aus Performancegründen. Bei SAP werden viele Datumsformate als Text gespeichert und beinhalten sicher immer ein gültiges Datum. In all diesen Fällen macht es Sinn, diese Datentypen bereits in der Stage beim Laden zu korrigieren.
Gather: Datenstrukturen prüfen
Es gibt eine Situation, in der eine Korrektur der Daten nicht sinnvoll möglich ist: Werden die Daten per Datei angeliefert und müssen in die Datenbank geladen werden, dann muss die Struktur der Daten korrekt sein. Während des Datenbankimport muss also sichergestellt werden, dass die Datenstrukturen geprüft werden.
Zusätzliche Logik für die Datenintegration
Ein Datenmodell beantwortet die Fragen: Welche Geschäftsobjekte gibt es im Unternehmen? Mit welchem Schlüssel identifiziere ich die Geschäftsobjekte? Welche Beziehungen haben diese Geschäftsobjekte? Welche Eigenschaften sollen dazu gespeichert werden?
Für die Datenintegration sind Geschäftsobjekt, Schlüssel und Beziehung wichtig. Leider gibt es selten die eine Sicht auf ein Geschäftsobjekt im Unternehmen. Je wichtiger etwas ist, desto mehr Definitionen gibt es dafür. Im Sinne des Prinzips‚ One Version of Facts – Multiple Truths‘ harmonisiert das BI Team diese Fragen in einen Faktenspeicher. Die Differenzierung erfolgt dann über vom Fachbereich spezifizierte Business Rules.
Hier liegt eine der zentralen intellektuellen Leistungen in der Entwicklung eines DWH: Die richtige Konzeption der Geschäftsobjekte aus den Datenmodellen der Quellverfahren und den Wünschen der Fachbereiche. Wird zu wenig gemacht, ist das Data Warehouse nur eine historisierte Version der Quellsysteme. Wird zu viel gemacht, muss u.U. für einen neuen Fachbereich ein Teil der Arbeiten zurückgebaut werden.
Gather: Daten normalisieren
Mitunter müssen die Dateninhalte gar nicht geändert werden, es ist ausreichend, lediglich die Attribute eines Geschäftsobjekt auf den gewünschten Schlüssel zu normalisieren. Hierunter fällt auch die Transformation von einem technischen Schlüssel zu einem Business Key. Dies wurde im Blogbeitrag ‚Datenschnittstellen aktiv gestalten zahlt sich aus‘ genauer ausgeführt. Es hat zudem den Vorteil, dass sich auf dieser Basis immer das korrekte Delta bilden lässt und so per Abstraktionsebene einheitliche Ladeprozeduren in den Raw Vault möglich macht.
Gather: Delta ermitteln
Zudem macht es Sinn, die Abstraktion aus diesem Papier in die Architektur zu übernehmen und die zu ladenden Daten als Delta zu speichern.
Nicht eindeutig: Generalisierung / Spezialisierung
Die Auflösung einer Generalisierung oder Zusammenfassung von Daten in einer Spezialisierung kann entweder auf dem Weg in den Raw Vault erfolgen oder später im Business Vault erfolgen. Hier sind die Wünsche gemäß des Geschäftsobjektmodells entscheidend. Deshalb wird dieser Punkt nicht gesondert im Architekturbild aufgeführt.
Apply: Komplexe Integrationslogik
Alle weiteren Aktionen zur Datenintegration sind komplex und benötigen eine genaue Spezifikation – Business Rules – durch den Fachbereich. Diese Anforderungen ändern sich im Zeitablauf und unterscheiden sich zwischen Fachabteilungen. Somit handelt es sich hierbei um Aktionen im Rahmen der Data Valorisation.
Apply: Komplexe Faktenlogik
Manchmal sind die richtigen Daten entweder nicht vorhanden oder schlichtweg falsch gespeichert. Dennoch lassen sich diese Daten mit Hilfe einer mehr oder weniger komplexen Logik berechnen. Meistens ist das einfacher und schneller, als die vorhandenen Systeme anzupassen. Mitunter können diese Daten auch gar nicht erfasst werden. Es fehlt die Zeit, die Gelegenheit oder die rechtliche Grundlage für diese Erfassung. Eine Schätzung oder Berechnung bleibt als einzige Alternative zurück. Wie jede Geschäftslogik ist auch diese Logik Änderungen unterworfen und sollte deshalb im Business Vault errechnet werden.
Das erweiterte Architekturbild zur Datenintegration
Das Architekturbild erweitert sich so um mehrere Arbeitsschritte. Jeder Arbeitsschritt ist optional und in der Grafik blau hinterlegt. Ein blauer Arbeitsschritt wird demnach also nur im Bedarfsfall durchgeführt.
Mit dieser genaueren Beschreibung lassen sich auch die einzelnen Schichten im Architekturbild genauer beschreiben.
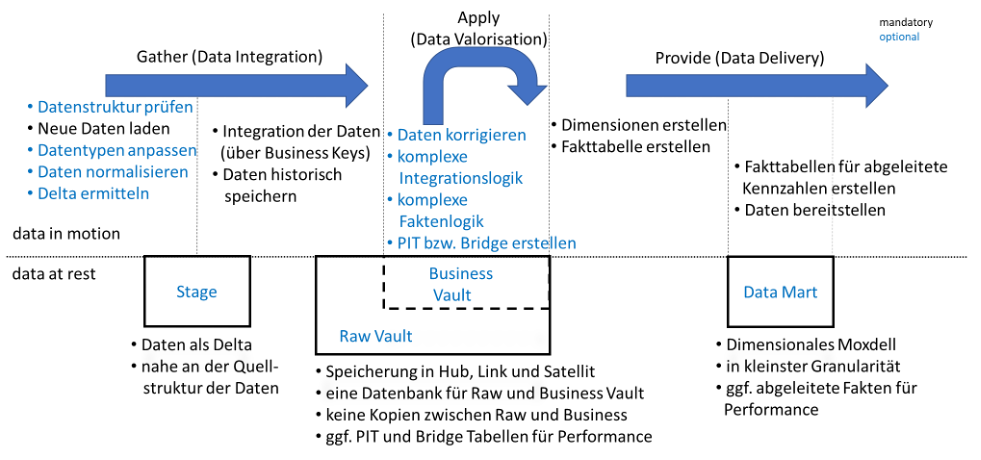
Dieses Architekturbild sorgt für eine Standardisierung der Data Warehouse Entwicklung. Wenn es etwas gibt, was nicht auf Anhieb in dieses Bild passt, kann man es hier integrieren und die Entscheidung über die Erweiterung für künftige Entwicklungen dokumentieren. Die Architektur wächst mit und an den Herausforderungen. Somit muss auch nicht immer das Rad neu erfunden werden. Man kann auf bestehende Lösungsmuster zurückgreifen. Die Gesamtzahl der verwendeten Muster sinkt – und damit sinkt auch die Komplexität, was wiederum Wartung und Pflege kostengünstiger macht. Die standardisierten Arbeitsschritte lassen sich automatisieren und die Entwicklungsgeschwindigkeit steigern.
Es stellt sich die Frage, ob diese Schritte überhaupt optimal sind? Schließlich wurde beim Schneiden der Arbeitsschritte ein grober Ansatz gewählt, um zunächst eine gemeinsame Gesprächsbasis zu entwickeln. Es braucht folglich einen Rahmen, nachdem sich dieses Architekturbild prüfen, bewerten und verbessern lässt. Das hierfür notwendige Modell wird im folgenden Blogbeitrag genauer beschrieben.