
Wenn man eine Weile mit Data Warehouse Automation arbeitet, merkt man, dass sich der Flaschenhals verschiebt. Der tatsächliche Zeitgewinn bleibt hinter dem Produktivitätsgewinn zurück. Sowohl DWH Automation als auch DataOps betrachten immer nur einen Ausschnitt des Data Warehouse. Das Data Warehouse ist ein System mit vielen Kommunikationsschnittstellen. Wenn Produktivität und Qualität verbessert werden sollen, muss das komplette System betrachtet werden. So entgeht man der Gefahr, ein lokales Optimum zu erschaffen, das an anderer Stelle teuer bezahlt werden muss.
Konzentration auf Leistungen und Informationen bringt Einheitlichkeit
Die kompletten Abhängigkeiten für ein Data Warehouse aufzuschreiben ist schwierig, da jedes Data Warehouse unterschiedlich organisiert ist und eine eigene Architektur hat. Jedes Unternehmen hat seine eigene Aufbauorganisation. Wer die Anforderungen an ein Data Warehouse stellt, ist jeweils unterschiedlich. Deshalb wird im Weiteren von Funktionen ausgegangen, mit denen in Zusammenarbeit eine bestimmte Leistung erbracht wird oder welche bestimmte Informationen zuliefern: Daten, Metadaten, Anforderungen. Unser komplettes System wird eine Abstraktion des Data Warehouse mit Fokus auf klare Schnittstellen und den Informationen, die an der Schnittstelle ausgetauscht werden.
Die Architektur des Data Warehouse besteht immer aus mehreren Schichten. Wie viele Schichten es braucht, ist eine lange Debatte. Viel wichtiger als die Schichten ist bei dieser Betrachtung jedoch die Funktionalität, die bereitgestellt wird. Denn jede Funktionalität braucht andere Informationen in den Anforderungen zur Umsetzung. Wenn wir die Umgebung nach Funktionen und Informationsaustausch organisieren, sollte das auch für das DWH gelten. Im Kern sind es 3 grobe Arbeitsschritte, die ein Data Warehouse erfüllt:
- das Sammeln und die Integration der Daten
- das Anreichern und die Korrektur der Daten je nach Anforderung
- das Bereitstellen der Daten
Vier Abhängigkeiten im technischen Bereich
Ermöglicht wird das durch den darunter liegenden Technologie Stack. Obwohl das Management dieses Technologie Stack bei kleineren Organisationen in der Hand des BI Teams liegen mag, ist
- die Auswahl der Technologie
- das Prüfen der Eignung
- die Einrichtung von Hard- und Software
- das Entwickeln von Richtlinien zur performanten Nutzung
- etc.
ein eigener Funktionsbereich.
Die Daten kommen von Quellsystemen und werden über einen definierten Schnittstellenmechanismus geliefert, aufbereitet und an ein oder mehrere Empfänger oder Front End Systeme wie Cognos, Qlik, tableau oder PowerBI geliefert. Empfänger von Datenexporten wurden hier den Front End Systemen gleichgestellt: beide erhalten Datenlieferungen.
Die Struktur der Datenlieferung sollte unabhängig vom jeweiligen Empfänger oder Front End erfolgen. Damit für weitere, andere Empfänger oder Front End nicht die Aufbereitung angepasst werden muss, sondern nur die Daten in die gewünschte Form gebracht werden. Dieses Vorgehen sichert einheitliche Ergebnisse über alle Auswertungen.
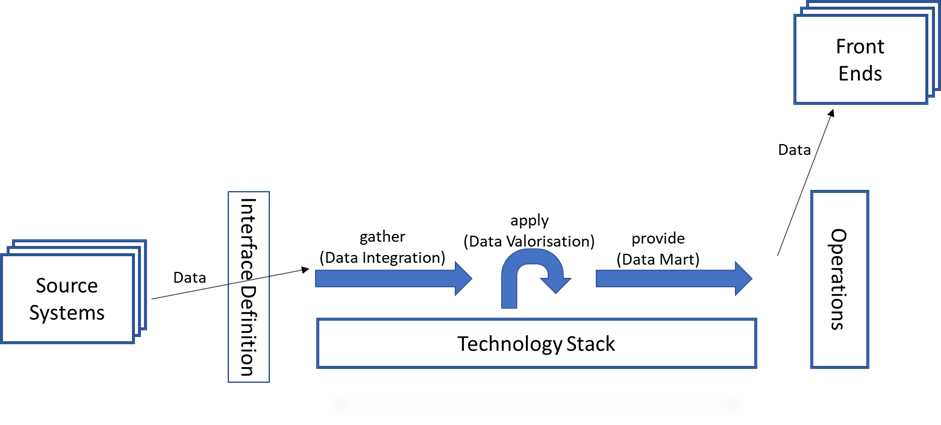
Zu guter Letzt gibt es noch einen Betrieb (Operations), der die regelmäßige Verarbeitung der Daten sowie den First bzw. Second Level Support durchführt.
Das sind vier der sieben Abhängigkeiten, wovon der Technologie Stack und der Betrieb im eigenen Einflussbereich liegen. Mit den Lieferanten und den Empfängern der Daten muss die Datenübergabe vereinbart werden. Diese Abhängigkeiten liegen alle bereits im aktuellen Scope von DWH Automation und DataOps.
Die Frage nach den Inhalten ist nicht in einer Abhängigkeit lösbar
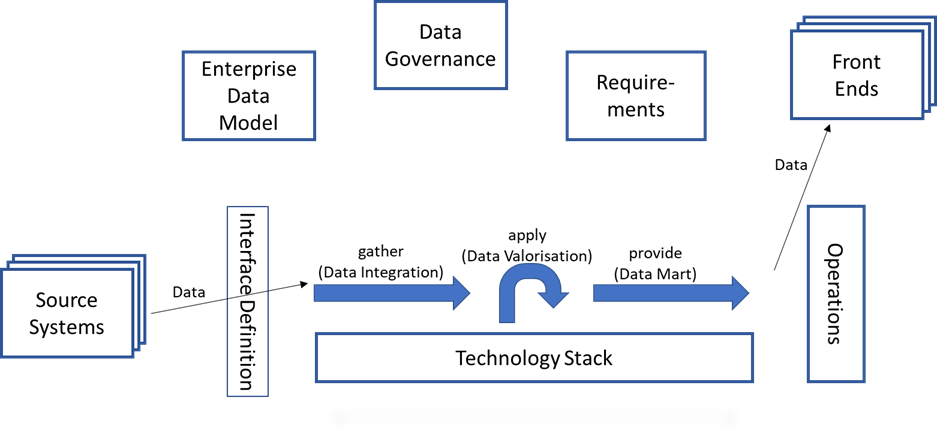
An dieser Stelle fehlt der komplette Bereich der Anforderungen. Untrennbar verbunden mit den Anforderungen ist die Frage: „Welche Daten stehen zur Verfügung?“. Hier lauert eine der größten Gefahren für ein Data Warehouse. Wenn das Unternehmensdatenmodell wenig bis gar nicht definiert wurde, dann kann ein BI Team beliebig viel Arbeit aufwenden, um diese Lücken zu schließen. Abgeschlossen wird dieser Komplex mit der Frage nach den Zugriffsberechtigungen bzw. dem Schutz der Daten wegen DSGVO oder wegen Arbeitnehmerüberwachung und einer etwaigen Genehmigungspflicht durch Betriebs- bzw. Personalrat. Diese Schutz- und Sicherheitsklassen werden typischerweise durch die Data Governance bereitgestellt.
Mit diesen 3 Boxen sind nun alle 7 Abhängigkeiten im Schaubild. Es mag im Einzelfall noch weitere Abhängigkeiten geben, doch mit den folgenden Informationen sind die meisten Anwendungsfälle abgedeckt:
- die zu verwendenden Daten – Enterprise Data Model
- die Zugriffsrechte und die Sicherheitsklassen der Daten – Data Governance
- die Anforderungen – Requirements
Das Unternehmensdatenmodell hilft nicht weiter
Wie bereits erwähnt ist die Frage nach dem Unternehmensdatenmodell in vielen Unternehmen keine gute Idee. Viele solcher Initiativen sind erfolglos geblieben. Der Grund liegt meist im Beharren auf einer einheitlichen Definition wohingegen unterschiedliche Verwendungszwecke häufig zu unterschiedlichen Definitionen führen. Das ganze Thema ist häufig eine große Kontroverse und lenkt vom schnellen Laden und Auswerten der Daten ab. Kann man diese Debatte vermeiden und dennoch valide Datenauswertungen liefern? Was braucht es eigentlich an Informationen, um erfolgreich ein Data Warehouse zu erstellen?
Es braucht eine Einigkeit mit den jeweiligen Auftraggebern über die zu verwendenden Daten. Hier hilft ein einfaches konzeptionelles Datenmodell, in dem die Geschäftsobjekte mit ihrem Business Key abgebildet werden. Ist kein Schlüssel verfügbar, ist auch das eine wertvolle Information. Ein solches Geschäftsobjektmodell ermöglicht eine schnelle Verständigung über die zu verwendenden Daten.

Zielgerichtete konzeptionelle Modellierung bietet mehr Möglichkeiten
Diese Geschäftsobjekte können mit den Daten aus den Quellsystemen verknüpft werden. Zudem kann aus diesem konzeptionellen Datenmodell das Schema für den Data Vault generiert werden. Eine genaue Ableitung von konzeptionell auf Data Vault ist im Artikel ‚Conceptual Data Vault Model‘ von Jovanovic und Bojicic beschrieben. Das Core Warehouse wird so vom konzeptionellen Modell bestimmt. Über die Zuordnung zur Quelle lassen sich die notwendigen Transformationen spezifizieren. Diese komplette Diskussion kann mit dem Fachbereich geführt werden. Mit Hilfe des konzeptionellen Modells entsteht eine gemeinsame Sprache, die in der Formulierung der Anforderungen verwendet werden kann. Mit dem Geschäftsobjektmodell entsteht ein Glossar der relevanten Daten.
Somit haben wir eine Brücke zwischen den Quellsystemen, den verwendeten Daten, den Anforderungen und der Data Governance geschlagen. Wenn nun der nächste interne Auftraggeber eine andere Sichtweise auf diese Daten hat, dann lässt sich diese in einem abweichenden Geschäftsobjektmodell beschreiben. Über die Zuordnung der Quelldaten können die Unterschiede anhand dieser Daten erklärt werden. Data Vault bietet mit der Kombination aus Raw Vault und Business Vault die Möglichkeit, die Unterschiede getrennt zu berechnen und die Abweichungen als Modellerweiterungen abzubilden. Eine Einigung ist nicht mehr nötig, das Data Warehouse kann mehrere Sichten auf dieselben Fakten bieten.
Das ist in dieser Form aktuell nicht immer üblich, spart dem BI Team jedoch alle Diskussionen über die Vereinheitlichung der Daten und konzentriert die Ressourcen auf die Bereitstellung der Daten. Dies bietet durch Ausschöpfen der eigenen Möglichkeiten eine Konzentration auf die zentralen Aufgaben. Zudem stellt sich die Frage, ob eine einheitliche Sicht der Daten immer so sinnvoll ist, wenn auf der Basis der Daten grundverschiedene Tätigkeiten betrachtet werden. Die Erfahrung zeigt, wenn die Unterschiede in der Sichtweise klar dargelegt sind, wird die Kommunikation für alle Beteiligten leichter. Es ist die Anerkennung der Fachkompetenz des anderen, die hier heilsam wirkt. Eine genauere tiefergehende Betrachtung wäre einen eigenen Artikel wert.
Gegebenenfalls muss eine Übersetzung vom Geschäftsobjektmodell zur Data Governance erfolgen. Idealerweise sind die Schutz- und Sicherheitsklassen bereits auf den Quelldaten definiert und liefern damit eine eindeutige Sicherheits- und Berechtigungsklassifizierung für das DWH. Wenn es keine Data Governance gibt, muss diese festgelegt werden. Die rechtlichen Regelungen zur DSGVO oder auch zur Mitbestimmung sind sehr eindeutig. Diese Verantwortung muss im Data Warehouse dementsprechend eindeutig geregelt werden.
Damit verändert sich das Schaubild wie folgt:
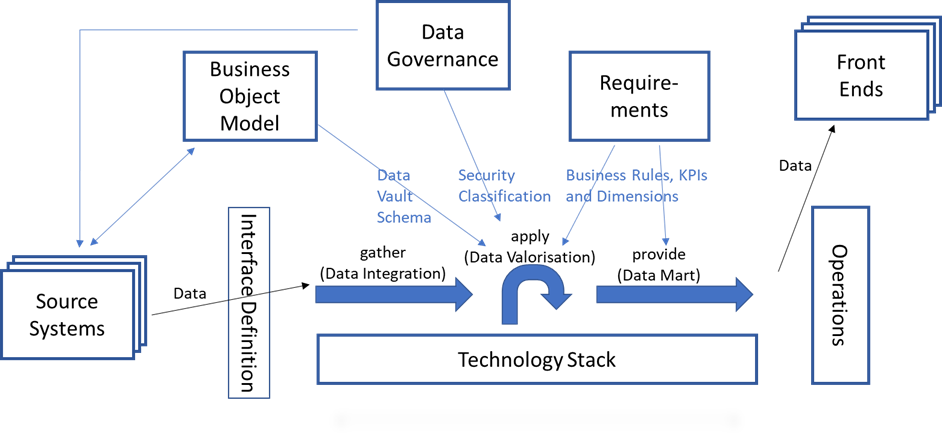
Komplette Sicht als Ausgangspunkt für übergreifende Verbesserungen
Die Gesamtzahl der Abhängigkeiten und der damit einhergehende Kommunikationsbedarf ist mit 7 Abhängigkeiten sehr hoch. Schaut man genauer auf die einzelnen Teile, entdeckt man Abhängigkeiten zwischen den sieben Bereichen. Schon in diesem schnellen Überblick lassen sich weitere Ansätze für eine verbesserte Zusammenarbeit finden. Durch die Konzentration auf Funktionen und deren Daten, Informationen und Anforderungen lässt sich die Zusammenarbeit anhand von Metadaten beschreiben. Mit diesen Metadaten können weitere Automatisierungen konzipiert werden.
Die Einteilung erlaubt eine klare Beurteilung, welche Aktivitäten für die Erstellung des Data Warehouse benötigt werden. Damit kann man nicht zielgerichtete Tätigkeiten auf die relevanten Bereiche reduzieren oder gar komplett streichen. Bei der Adaption auf eine eigenes Data Warehouse ist das Bild der Abhängigkeiten abzugleichen und ggf. zu ergänzen. Gleichzeitig stellt sich sofort die Frage, ob diese wirklich für die Erstellung des Data Warehouse benötigt werden.
Als nächstes gilt es Kennzahlen festzulegen, mit denen sich Performance und Qualität in diesem System überwachen lassen. Dann hat man neben dem Modell des Systems auch die Kenngrößen für eine konstante Verbesserung des Data Warehouse.